ROUND-1 WARM-UP PROBLEMS
Solutions
Minute Mayhem: Imagine two clocks locked in a timeless dance, each with its unique tempo.
One clock, a time-losing maverick, steadily sheds 5 minutes per hour, while its counterpart, a time-gaining maestro,
eagerly accumulates an extra 5 minutes with each passing hour. If these eccentric timekeepers synchronized at noon on a Tuesday,
how many hours will waltz by before they start displaying the symphony of simultaneous time?
Shuttling to Success! In the riveting badminton arena, where shuttlecocks soar and dreams take flight,
imagine yourself as one of the 128 valiant contenders. In this intense quest for supremacy, every match is a decisive battle
where only the triumphant advance to the next round. As you embark on this journey, eager to seize victory, contemplate this question:
What number of matches must you conquer to stand proudly on the precipice of the semi-finals, where the echoes of shuttlecock clashes
and the sweet taste of triumph propel you forward?
![]()
Numeric Mystery: Can you predict the last digit of $$2004^{2024}$$
Mystic Grid Strategies: Dive into the captivating realm of an 8x8 chessboard, where numbers from 1 to 64 are placed in order. Picture yourself as the strategic architect,
selecting 8 squares with precision - one from each row and one from each column. As you orchestrate this symphony of choices, what magical sum materializes when you
add up the numbers residing in your carefully chosen squares?
![]()
Data Cleaning Dilemmas: Data Scientists tackle a wide range of real-life problems using data and various techniques. Alfred was given a task to classify a corpora
of some 20k tweets scraped from the web-platform X, into some categories. Now, the texts contained various irrelevant characters (emojis, punctuations, tags, links, etc) and he decided to do some data cleaning in order to optimise the model's
performance.
![]()
import pandas as pd
import re
import emoji
data = pd.read_csv('/content/tweets.csv') #Reading the corpora
def preprocess_tweet(tweet):
tweet = tweet.lower() #Step-1
tweet = re.sub(r'http\S+|www\S+', '', tweet) #Step-2
tweet = ''.join(c for c in tweet if c not in emoji.UNICODE_EMOJI) #Step-3
tweet = re.sub(r'[^a-zA-Z0-9\s]', '', tweet) #Step-4
return tweet #newly cleaned tweets
data['tweet'] = data['tweet'].apply(preprocess_tweet)
According to you, which among the steps performed is not rationally correct and might reduce the model efficiency?
Weather Driven Decisions! Rahul had a dataset containing columns 'Outlook', 'Humidity', 'Wind' and 'Status (Played Football: Yes/No)'.
Clearly, the independent variables (Outlook, Humidity, and Wind) would decide the dependent variable (i.e. whether to play football or not). He uses the ID3 algorithm
to build a decision tree from the data, which has been shown below:
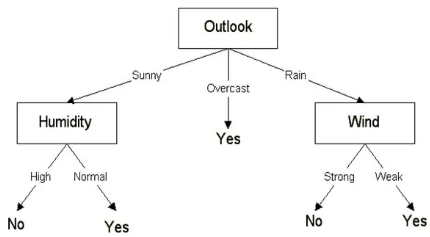
Further note that a 'Yes' is depicted by a '1' and a 'No' by a '0'. Predict the output (in respective order) if the rows of data provided as input were:
# COLUMNS: OUTLOOK, HUMIDITY, WIND
Sunny, Normal, Weak #Row1
Overcast, High, Strong #Row2
Rain, High, Strong #Row3
Sunny, High, Weak #Row4
Sunny, High, Strong #Row5
Exploring Shapes: If 'O' is the center of the circle, predict the area of the shaded portion (in sq. cm)
